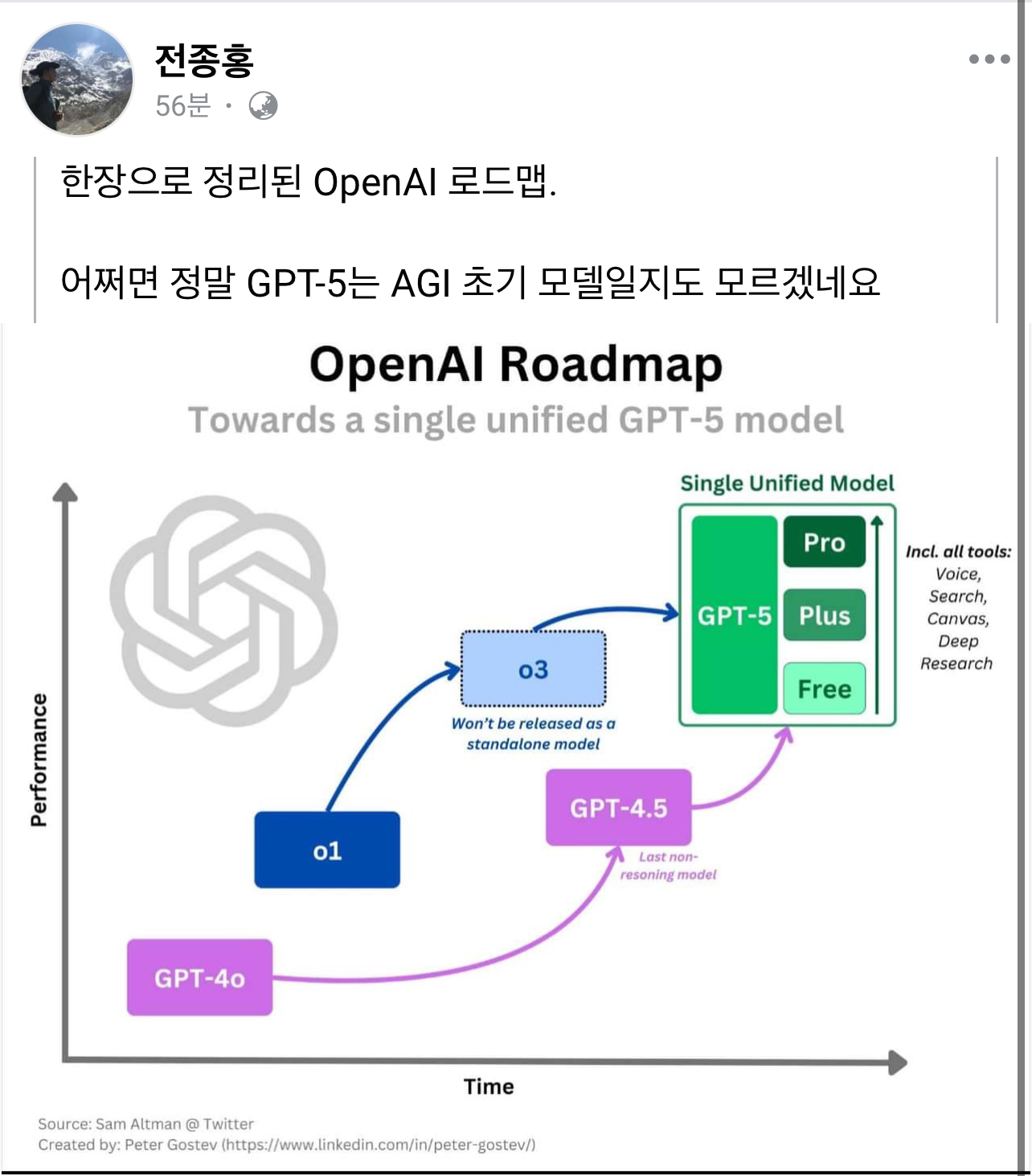
——
오늘 샘 알트만의 트윗을 보고 생각이 나서 가져와봤습니다
——
레딧에서 AI 관련해 여러번 옳은 예측을 하고, 일명 '현자'로 일컬어지는 유저가 쓴 블로그 포스팅입니다. 상당히 깊이 있고, 논리적으로 외삽하고 있으니 한번 읽어봅시다.
https://ldjai.substack.com/p/addressing-doubts-of-progress
Addressing doubts of AI progress
ldjai.substack.com
AI 발전에 대한 의구심 해소
AI 발전의 큰 그림에 대한 오해를 다룹니다. 왜 GPT-5가 늦지 않았는지, 왜 합성 데이터(synthetic data)가 유효한지, 그리고 앞으로의 18개월 동안의 진전이 지난 18개월보다 클 것이라 예상하는 이유를 설명합니다.
요약:
Compute Scaling Expectations(컴퓨팅 스케일링 기대치): 첫 번째 GPT-4.5 규모 클러스터들은 불과 몇 달 전부터 모델 훈련을 시작했으며, 첫 번째 GPT-5 규모 클러스터들은 2025년 후반에 구축될 것으로 예상됩니다.
"GPT-5는 늦었다/기한을 넘겼다"는 주장: GPT-3에서 GPT-4가 출시된 시점을 단순 외삽해도, GPT-5 출시 시점은 2025년 12월 정도로 추정됩니다. 일부가 암시하듯 훨씬 더 이른 시점이 아니라는 것입니다.
"데이터의 한계(Data Wall)": 웹 텍스트의 한계가 실질적으로 가까워지고 있으나, 멀티모달 데이터, 특히 합성 데이터(synthetic data)가 계속된 진전을 이끌어내고 있습니다.
"합성 데이터의 역할(The Role of Synthetic Data)": 합성 데이터를 위한 데이터 선별 파이프라인(data discrimination pipelines)과 더욱 발전된 훈련 기법이 모델 붕괴(model collapse)와 같은 문제를 회피하도록 돕습니다. 합성 데이터는 이미 코딩 및 수학 분야에서 매우 뛰어난 이점을 제공하고 있으며, 이는 동일한 컴퓨팅 규모에서 추가 웹 텍스트 데이터가 제공했을 이점 이상일 가능성이 높습니다.
인터페이스 패러다임(Interface Paradigms): 모델 능력의 도약에 대한 인식은 단순히 컴퓨트 규모, 아키텍처, 데이터 때문만이 아니라, 모델을 사용하는 실제 인터페이스에도 크게 좌우됩니다. 만약 GPT-4가 원래의 GPT-3나 GPT-2와 동일한 인터페이스 패러다임에 묶여 있었다면, 결과적으로 우리는 창의적인 용도의 이야기 완성 시스템 수준의 활용에 그쳤을 것입니다.
결론(Conclusion): 2025년에 접어들수록, 더 대규모의 컴퓨팅, 합성 데이터, 새로운 훈련 기법, 그리고 새로운 인터페이스 패러다임이 융합되면서, 많은 사람들이 AI 발전에 대해 가지는 관점이 크게 달라질 것이라고 믿습니다.
Section 1: Personal predictions
먼저, 제가 현재 어떤 높은 수준의 관점에서 AI 진전이 어디로 향하고 있다고 보는지 말씀드리겠습니다.
2024년 12월 2일, 저는 오랫동안 여러 가지를 숙고한 끝에, “앞으로의 18개월간 대중이 보는 AI 진전의 양이 지난 18개월보다 더 클 것 같다”고 온라인에서 한 친구에게 말했습니다(제 확신도는 약 90%입니다). 이후 12월 13일에는 좀 더 근접한 예측(확신도 ~75%)을 했습니다. 즉, “2024년 12월 13일부터 2025년 4월 29일 사이의 약 4.5개월 동안, 지능과 유용한 기능 모두에서의 ‘공개된 최전선 AI(progress in public frontier AI)’가, 2023년 6월 13일부터 2024년 12월 13일까지의 18개월 동안 이뤄진 진보를 합친 것보다도 더 많을 것이다.” 라고 예측했습니다. 그리고 이후 “진보”가 무엇이었는지를 나중에 평가할 수 있도록 일부 측정 기준을 제시했습니다. 며칠 뒤인 12월 20일, OpenAI가 O3 모델을 발표했습니다. 저는 이 두 번째 예측에 더더욱 확신을 가지게 되었는데, 이는 O3 때문만이 아니라, 향후 발표될 것으로 예상되는 다른 모델/기능들 때문이기도 합니다.
2024년 내내, 저는 회의적인 친구나 가족, 지인들과 대화를 많이 나눴습니다. 그들은 AI가 속도를 늦추고 있다거나, 벽에 부딪혔다거나, 혹은 진전이 과장되어 있다고 믿는 편이었습니다. 처음 듣기엔 그들의 주장(“인터넷 데이터가 고갈되었다”, “합성 데이터는 모델 붕괴를 일으킨다”, “GPT-5는 늦어지고 있다/기한을 넘겼다”)이 타당해 보이기도 했습니다만, 저는 이러한 의견에 대해 “실질적인 둔화는 아니다”라는 근거를 들어 종종 반박하곤 했습니다. 최근 몇 달 동안 제가 이 글을 준비하는 동안, 실제로 새로운 모델이 일부 공개되면서 회의론이 어느 정도 약해지는 모습을 봤고, 온라인에서 자주 회의적인 의견을 내던 사람들도 한층 조용해진 듯합니다. 그러나 많은 사람이 근본적인 오해를 바로잡은 것이 아니라, 단지 몇 달간 조용하다가 새로 나온 ‘멋진’ 모델을 보고 그저 표면적인 이유로 입장을 바꾼 것 같다는 느낌도 있습니다. 이 글에서는 제가 “아주 가까운 미래의 낙관론”을 가지게 된 모든 이유를 세세히 밝히지는 않겠습니다. 다만, “진전을 의심하는” 사람들이 흔히 제기하는 주요 논점들에 대해 집중적으로 이야기해보고자 합니다.
Section 2: Compute Scaling Expectations
GPT-2에서 GPT-3로, 그리고 GPT-3에서 GPT-4로의 도약은 각각 약 100배의 순수 훈련 컴퓨팅 증가를 수반했습니다. GPT-4에서 GPT-4.5로 가는 “반걸음(hypothetical half-step)”조차도 동일한 추세를 따른다면, 약 10배에 달하는 컴퓨팅 도약이 필요하며, 이는 대략 H100 GPU 8만 장(80K H100s) 정도가 필요하다는 의미입니다. 이 분야에서 가장 신뢰할 만한 분석가들을 따르면, 그러한 규모의 훈련 클러스터는 2024년 중반에야 처음으로 존재하게 된 것으로 보이며, 마이크로소프트/오픈AI가 약 10만 장 규모의 H100을 갖춘 클러스터를 구축했을 것으로 추정됩니다. 뒤이어 XAI가 유사한 규모의 클러스터를 구축했다고 몇 달 뒤 공식 발표했으며, 최근에는 구글도 TPU 클러스터 형태로 비슷한 컴퓨팅 규모를 확보했을 가능성이 있다고 알려졌습니다.
이러한 클러스터들은 이제(혹은 얼마 전) 2024년 4분기부터 첫 번째 GPT-4.5 규모의 모델을 훈련하고 있으며, 저는 이러한 모델들이 2025년 1분기에 처음 대중에게 공개될 것으로 예상합니다. 어떤 이들은 “이제는 GPT-4와 비교했을 때, 지난 2년간의 알고리즘 발전 덕에 (GPT-4.5에) 더 큰 도약이 있을 것이다”라고 말하지만, 이 점은 일견 타당해 보여도, GPT-3에서 GPT-4로의 도약 자체가 추정치로 약 100배의 ‘순수’ 컴퓨팅 증가와 추가로 약 10배의 효율성 향상을 합쳐서 총 1,000배가량의 ‘실질적(effective)’ 컴퓨팅 도약으로 평가된다는 점을 감안해야 합니다(이는 Leopold Aschenbrenner, EpochAI 등을 비롯한 여러 곳에서 추정한 바입니다). 따라서 GPT-4에서 GPT-4.5로 가는 과정에서 동일하게 10배의 효율성 향상이 있다고 하더라도, 결과적으로는 약 100배의 종합적 도약에 불과해, GPT-3에서 GPT-4 사이에 추정된 약 1,000배와 비교하면 훨씬 적은 규모가 됩니다. 그러므로 최근 내부적인 진전이 “GPT-3에서 GPT-4 사이에 비해 덜 놀랍다”는 식의 뉴스 기사나 보고서들은 전혀 놀라운 일이 아닙니다. 이는 제가 예상했던 대로이기도 합니다.
(GPT-4 현재 수준은 1e26 수준이며 다음 단계는 1e27, GPT-5는 1e28)
앞을 내다보면, Nvidia의 Blackwell GPU가 더 거대한 클러스터를 가능케 하여, GPT-5 규모에 비교적 빠른 시점에 도달하게 될 것입니다.
XAI는 2025년 중반쯤에 약 30만 장(300K) B200 규모의 클러스터를 구축할 계획을 밝혔고, OpenAI와 Microsoft 역시 비슷한 시기와 비슷한 규모를 목표로 한다고 추정되고 있습니다. 참고로, B200 GPU 20만 장(200K B200) 규모의 클러스터만 있어도 약 3개월 만에 GPT-5 규모 모델을 훈련할 수 있으므로, 2025년 말 혹은 2026년 초에 출시되는 것이 충분히 현실적인 시나리오입니다.
물론 한 지역에서 전력망을 통해 끌어올 수 있는 전력에 한계가 있으므로, 막대한 컴퓨팅 자원을 구축하려면 에너지 인프라에 관한 우려가 제기되기도 합니다. 하지만 분산 훈련(distributed training)—예를 들어, 단일 훈련 과정에 여러 개의 훈련 캠퍼스를 동시에 활용하는 방식—이 조만간 더욱 실용적이고 빈번하게 사용될 것으로 예상되어, 향후 18개월간 단일 모델에 투입되는 컴퓨팅 규모가 한층 가속화될 가능성도 있습니다. 따라서 최소한 앞으로 12~18개월 동안은 에너지 제약 때문에 GPT-5급 모델 훈련이 본질적으로 제한될 가능성은 점점 낮아지고 있습니다. (여기서 SemiAnalysis의 관련 기사는 여러 캠퍼스에 걸친 훈련 계획과 에너지 수요에 대한 최신 상황을 잘 정리해줍니다.)
Section 3: "GPT-5 is late/overdue"
많은 사람들이 “GPT-5는 늦어지거나 이미 기한을 넘겼다” 라는 인식을 갖고 있으며, 이를 두고 ‘스케일링 법칙(scaling laws)이 깨졌다’, ‘더 이상 훈련할 데이터가 남아있지 않다’ 등의 이유로 설명하는 경우가 있습니다. 한편 낙관론자 중에는 **“GPT-5급 모델이 수개월 혹은 수년째 숨겨져 있을 것”**이라고 믿는 사람들도 있습니다. 저는 이 두 견해 모두, 이전 세대 모델들이 공개되던 시점 및 필요했던 컴퓨팅 스케일에 대한 근본적인 오해가 동일하게 깔려 있다고 봅니다. 그리고 결과적으로 GPT-5는 전혀 늦은 것이 아니라고 생각합니다.
많은 기대치가 GPT-3.5가 처음 ChatGPT에 탑재된 시점에서부터, GPT-4가 공개되기까지 걸린 대략 4개월에 근거합니다. 그때를 떠올려보면 확실히 빠르게 진전된 시기였으므로, 사람들은 “그렇다면 GPT-4.5와 GPT-5도 최대 4~8개월, 혹은 길어도 16개월 이내엔 나와야 하는 것 아니냐”라고 추론하는 것입니다.
하지만 실제로는, GPT-4는 GPT-3.5가 ChatGPT에 공개되기도 전에 이미 훈련이 완료된 상태였습니다. 원래 ChatGPT는 전체 GPT-4를 공개하기에 앞서, 사람들이 해당 인터페이스를 어떻게 사용하는지 ‘미리보기(preview)’ 형태로 확인하기 위한 더 적합한 지점이었습니다. 결국 GPT-3의 초기 버전과 GPT-4 출시 사이에는 **약 33개월(2년 반 조금 넘는 기간)**의 공백이 있었는데, 이것이 바로 GPT-4 개발에 필요한 대형 클러스터 구축 및 관련 연구를 마무리하는 데 걸린 실질적인 시간입니다.
이와 동일한 33개월의 간격을 GPT-4 이후로 단순 외삽하면, GPT-5의 출시 시점은 2025년 12월로 추정됩니다.
(이 부분에 관해서는 SemiAnalysis가 여러 해에 걸친 인터커넥트, 클러스터 확장 문제와 이를 어떻게 해결했는지에 대한 훌륭한 분석 기사를 제공하니 참고할 만합니다.)
Section 4: The Data Wall
인터넷에서 얻을 수 있는 고품질(unique) 텍스트 데이터의 한계인 일명 “데이터의 벽(data wall)”은 분명 유효한 걱정거리입니다.
Common Crawl의 인터넷 아카이브를 보면 약 100조(100T) 토큰 정도의 텍스트가 있지만, GPT-4에 대해 흔히 알려진 바로는 **6조(6T) 토큰 미만의 ‘고유(unique) 데이터’**를 사용했다고 합니다. (물론 여러 차례 반복 학습(에폭) 때문에 기술적으로는 13조 토큰을 사용했다는 이야기도 있습니다.) 문제는, 오픈소스 Dolma 등의 필터링 작업을 보면 알 수 있듯, 중복 제거(deduplication)와 기본적인 품질 필터링을 거치면, Common Crawl의 텍스트 데이터 중 80% 이상이 걸러진다는 것입니다. 따라서 유용하고 고품질의 공개 텍스트 데이터가 실질적으로 이미 한계점에 근접했다는 견해가 제기되는 것도 어느 정도 타당합니다. 물론 독점(프로프라이어터리) 데이터나 **멀티 에폭 훈련(동일 데이터 반복 노출)**을 통해 어느 정도 보완할 수 있겠지만, 산업계의 중론은 **“유용하고 고유하며, 원천적으로 존재하는 데이터”**가 비교적 가까운 시기에 한계점에 이를 것이라는 쪽에 가깝습니다.
한편 멀티모달(multi-modal) 토큰 데이터를 보면, 특히 비디오처럼 웹 텍스트보다 10배 혹은 100배 이상의 양이 존재한다고 추정되어, 향후 훈련 가능성을 크게 확장할 여지도 있습니다. 다만 이렇게 멀티모달 데이터를 활용할 때의 개선 방향은 과거와 전혀 다른 형태가 될 수도 있어 예측이 어렵습니다. 그럼에도 불구하고, 많은 이들이 이보다 더 큰 잠재력을 지닌다고 보는 것이 **합성 데이터(synthetic data)**입니다.
(*이 부분이 상당히 흥미롭습니다. 최근 프론티어 랩들에서 사용하는 멀티 에폭 트레이닝도 큰 효용을 보긴 어렵고 결국은 합성데이터로 간다는 이야기)
Section 4.5: The Role of Synthetic Data
이 맥락에서 말하는 **합성 데이터(synthetic data)**란, AI가 생성한 데이터를 다시 차세대 모델 훈련에 사용하는 것을 의미하며, 데이터 부족 문제를 해소하는 중요한 열쇠로 주목받고 있습니다. 진전을 의심하는 일부 사람들은 “합성 데이터는 무분별하게 사용하면 모델 붕괴(model collapse)를 일으킨다”는 논문을 인용하기도 합니다. 하지만 실제 대규모 합성 데이터 연구들은 무분별한 사용과는 거리가 먼, 고도로 선별적(discriminate)인 활용 방식을 향해 가고 있습니다.
최근에는 낮은 품질의 데이터를 걸러내기 위해 정교하게 선택된 파이프라인을 활용하고, 생성된 데이터의 고유성(uniqueness)과 다양성을 극대화하며, 다양한 품질 지표를 사용해(이때는 별도의 라벨링 모델이 동원됨) 데이터를 평가하고, 코드·수학 분야처럼 기능적으로 검증이 가능한 영역에서 **검증 알고리즘(functional verifier)**을 사용하기도 합니다. 또 어떤 경우에는 합성 데이터 생성을 **인간이 만든 소스 데이터(human sourced data)**에 직접적으로 연결(grounding)하기도 합니다. 최근에는 아예 훈련 과정 중간에 데이터를 생성하고 가지치기를 반복하는 고급 파이프라인까지 연구되고 있습니다.
이러한 방식은 특히 코딩(coding)이나 수학(Math) 같이 기능 검증(functional verification)이 가능한 분야에서 큰 성과를 거둡니다. 예컨대 Llama-3.1은 코드 실행 피드백을 통해 여러 번에 걸쳐 스스로 코딩 능력을 개선하는 기법으로 훈련한 것이 확인되었습니다. 보다 개방형(open-ended) 과제에 대해서도 Meta가 연구 중인 “meta-rewarding language models” 같은 모델 자체 평가 및 자기개선 기법이 등장하고 있으며, 이때는 기능 검증이 없는 영역에서도 어느 정도 성능 향상을 이룰 수 있다고 합니다.
또 다른 예로 Deepseek V3는 합성 데이터의 가능성을 대규모로 입증해 보였는데, 작은 모델 자체를 개선하는 것을 넘어, 예전의 추론 기반 R1 모델(대략 o1 미리보기 모델 수준의 역량과 행동 방식을 가진 모델)을 이용하여 새로운 대형 채팅 모델을 개선하는 **지식 증류(distillation)**를 수행했습니다. 그 결과 R1에서 Deepseek V3로 이식(교수-학습)하는 과정을 거친 뒤, 유명한 수학 올림피아드 예선(AIME)에서 39% 점수를 얻었습니다. 참고로 GPT-4나 Claude-3.5-sonnet는 이 시험에서 18% 미만의 점수를 받습니다. 또한 Deepseek V3 모델은 **코드포스(Codeforces)**와 MATH-500 벤치마크에서도 4o나 최신 Claude보다 크게 우수한 성능을 보였습니다.
Section 5: Interface paradigms
저는 우리가 GPT-3에서 GPT-4로 넘어가면서 느낀 인상이 흔히 “단지 스케일 확대로만 달성된 것”이라고 여겨지지만, 실제로는 모델을 체험하는 과정에서 근본적으로 달라진 인터페이스가 큰 역할을 했다고 생각합니다. 즉, 스토리 완성(story-completion) 방식에서 채팅(chat) 방식으로 전환된 변화가 그 핵심입니다.
만약 GPT-4가 GPT-2나 GPT-3처럼 “스토리 완성 모델”로만 공개되었다면 어떨까요? 사용자는 이야기의 첫 부분만 입력하고, 모델이 나머지를 이어 쓰는 식으로 활용하는 정도에 그쳤을 겁니다. GPT-3.5와 GPT-4가 완전히 새로운 형태의 인터페이스를 채택하고(또 이 새로운 패러다임의 잠재력을 극대화하기 위한 새로운 후속 훈련 기법을 적용했다는 점도 중요합니다) 이를 통해 사용자에게 실제로 드러나는 지능과 역량이 크게 바뀌었다는 사실을 간과해서는 안 됩니다.
물론 채팅 인터페이스(chatbox)는 전반적인 활용도와 유용성 면에서 엄청난 도약이 맞지만, 미래에 모델의 지능을 ‘완전히’ 개방할 수 있는 최고의 혹은 최종 인터페이스인지는 확신하기 어렵습니다. 개인적으로는 음성 모드(voice mode)나 현재의 O1 인터페이스조차도, 크게 보면 여전히 같은 채팅 패러다임의 일부분이라고 봅니다.
그리고 “새로운 인터페이스 패러다임을 찾아서 GPT-4를 그냥 거기에 얹으면 된다”처럼 간단한 문제도 아닙니다. GPT-3.5와 GPT-4가 나오기 훨씬 전부터, 예컨대 Character AI나 AI Dungeon 같은 GPT-2~3급 모델의 채팅 버전이 이미 1년 이상 온라인에 존재했었죠. 하지만 그 시도의 경우, 모델의 기본 지능과 능력이 충분히 강력하지 않았기에 실제로 크게 유용하게 쓰이지 못했습니다. 그래서 AI Dungeon이나 Character AI는 일부 창의적 니즈가 있는 얼리어답터들 사이에서만 사용되었고, ChatGPT 같은 폭발적 반응을 일으키지는 못했습니다.
그렇다 해도, 2019~2022년에 등장한 이런 GPT-2급 채팅 시도들을 보고 “너무 불안정하다”는 이유로, 대형 언어 모델(LLM)은 “결코 일반 대중이 쓸 만한 챗봇이 될 수 없다”고 단정 지었다면, 그것은 엄청난 착오였을 것입니다.
Section 5.5: The coming era of CUA (Computer Using Agents)
저는 우리가 이제 **“ChatGPT 시대”**가 에이전트, 특히 CUA(Computer Using Agents) 중심으로 전개되는 문턱에 와 있다고 생각합니다. 즉, 모델이 데스크톱 화면을 보고 제어하면서, 여러분을 위해(혹은 여러분과 함께) 작업하는 모습을 상상해보세요. 혹은 모델이 자신의 마우스 커서를 직접 움직이면서(여러분의 마우스 커서와 함께), 디스코드로 화면을 공유하듯 대화를 주고받고, 동시에 그 프로젝트에 즉석에서 마우스 클릭이나 입력을 하며 자연스럽게 협업하는 장면을 생각해보세요. 이 모델은 미래의 상호작용에서 중요할 수 있는 요소들을 꾸준히 기억해두기도 합니다.
이미 “유용한 에이전트”를 만들려는 시도가 많았지만, 저는 그것들이 아직 시기상조라고 봅니다. 가장 큰 이유는 지금까지 모델들이 갖춘 컴퓨팅 스케일과 지능/역량이 충분하지 않았기 때문입니다. Rabbit R1이나 Humane 같은 제품들도 이론상 훌륭한 아이디어를 제시하지만, 그 시점 모델의 역량으로는 신뢰도나 속도, 비용 효율 면에서 요구되는 기준에 전혀 못 미치는 에이전트 기능을 과도하게 약속했다는 문제가 있었습니다.
하지만 “트랜스포머 모델 아키텍처는 본질적으로 신뢰할 만한 에이전트 능력을 구현할 수 없다”고 주장하는 사람들도 그저 GPT-2나 GPT-3 시절에 “LLM은 결코 대중적으로 유용한 챗봇이 될 수 없다”고 말했던 이들과 같은 중대한 오류를 범하고 있다고 생각합니다.
실제로 지난 8개월간 공개된 Claude artifacts 기능, Vercel의 V0, 그리고 Claude computer-use 등은 꽤 인상적인 사례입니다. 그럼에도 저는 이들이 에이전트 패러다임 관점에서, AI Dungeon이나 Character AI에 더 가까운 제품이라고 봅니다. 예를 들어, Anthropic computer-use 기능은 개발자 전용 API 접근에 한정되어 있고, 비용이 비싸고 느리며, 특정 제한된 용례 밖에서는 여전히 안정적이지 않습니다. 이는 마치 원래 AI Dungeon이나 Character AI 유저들이 갖고 있던 소수 취향(niche) 사용자층을 떠올리게 하죠.
하지만 앞으로 6개월~18개월 사이에는, 신규 GPT-4.5 규모 모델(그리고 곧이어 GPT-5 규모 모델) 출시, 그리고 그러한 모델들과 파생 모델들의 에이전트 신뢰도·멀티에이전트 능력·비용 및 속도 개선을 위한 새로운 훈련 기법이 적용되면서, 이 분야의 여러 장애물들이 상당 부분 해소되고 에이전트 역량에서 큰 도약이 일어날 것이라 예상합니다. 그리고 이러한 발전이 모여서 에이전트를 위한 ChatGPT 시대가 도래할 것이라고 믿습니다.
좀 더 단기적으로는, 모델에게 “매달 한 번씩 최신 오픈소스 AI 출시 소식들을 정리해, 1,000단어 분량의 심층 보고서를 만들어달라”와 같은 장기·주기적 업무를 손쉽게 위임할 수 있는 기능이 중요할 것 같습니다. 모델이 스스로 대화를 시작하거나, 특정 작업 단계를 어떻게 수행해야 할지 묻는 식으로 사전적 소통을 할 수도 있을 것입니다. 이론적으로는 현재 모델로도 어느 정도 구현 가능한 기능이지만, 현실적으로는 이를 GPT-4급 모델에 강제로 적용하면 신뢰도 문제나 사용자 만족도 저하, 귀찮음 등 여러 문제가 생길 수 있습니다. 따라서 이런 기능 중 좀 더 고급스럽고 안정적인 형태들은 적어도 향후 3개월에서 18개월 정도에 걸쳐, 새로운 모델들이 출시되면서 단계적으로 구현되고, 점차 높은 수준의 복잡성과 유용성을 갖추게 될 가능성이 높습니다.
Conclusion
이상에서 말씀드린 여러 요인들—앞으로 12개월간 예고된 100배 이상 규모의 훈련, 이미 그 유효성을 입증한 합성 데이터, O1 등에서 활용되는 고급 RL 같은 새로운 훈련 기법, 그리고 CUA와 같은 새로운 인터페이스 패러다임—이 결합되면서, 2025년에는 많은 사람들이 AI 진보를 바라보는 시각이 크게 달라질 것으로 보입니다. AI의 발전을 의심하는 목소리는 점점 더 드물어질 것입니다.
앞으로는, GPT-3.5와 GPT-4 사이의 4개월 공백 같은 매우 단기적 지표를 근거로 추세를 단순 외삽하여, 실제 상황을 훨씬 낙관적으로 보는 실수를 범하지 않도록 주의해야 합니다. 컴퓨팅 스케일의 진짜 진전과 공개된 모델의 역량 간의 관계를 제대로 이해하려면, 시간에 따른 클러스터 규모 추이를 살피는 것이 가장 유용한 단일 지표일 가능성이 큽니다. 결론적으로, GPT-5는 늦지 않았고, 합성 데이터는 충분히 가치가 있으며, 가까운 미래의 AI 발전은 매우 밝을 것으로 보입니다.